ClickHouse® Dictionaries Benchmarking


Preface
There are few ClickHouse benchmarks in the web already. Most of them use denormalized database schema. However, in denormalization is not always possible or desirable. In this article we will compare the query performance between denormalized and normalized schema where normalization is modelled using unique ClickHouse external dictionaries feature.
We take public known dataset of New York taxi trips which was used and described here and here. This dataset contains ~1.3 billion individual taxi rides along with some external data such as weather conditions and taxi zones profiles.
Hardware
All tests are performed on a single server and 3-node cluster. Physical servers are running Debian Linux 3.16 on an Intel® Core™ i7-6700 Quad-Core Skylake, 2x4TB SATA HDD.
ClickHouse
ClickHouse can be easily installed from from pre-made packages.
$ echo "deb http://repo.yandex.ru/clickhouse/trusty stable main" |
sudo tee -a /etc/apt/sources.list
$ sudo apt-key adv
--keyserver keyserver.ubuntu.com
--recv E0C56BD4
$ sudo apt-get update
$ sudo apt-get install
clickhouse-client
clickhouse-server-commonAnd started.
$ sudo service clickhouse-server startClickHouse Cluster Specific Steps
For the cluster configuration we will also need to configure every server node separately. Since we have an intranet LAN for all servers in the cluster we will need to update config.xml so each CH instance will listen a proper LAN host.
<listen_host>192.168.*.*</listen_host>The next required step in ClickHouse cluster configuration is to define ‘remote_severs’ XML element. We will use include feature element for that matter. Include works the way that some sections could be substituted by elements from other file. So let’s create a file /etc/metrika.xml (which is default substitution file for elements in CH) with the following content:
<yandex>
<remote_servers>
<taxi>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>192.168.11.3</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>192.168.11.2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>192.168.11.1</host>
<port>9000</port>
</replica>
</shard>
</taxi>
</remote_servers>
</yandex>Here we define 3 ClickHouse nodes with their IPs and ports. This configuration should be translated to each server in the cluster.
Loading Dataset into ClickHouse (Denormalized)
We will use the same process of importing the data into ClickHouse as it was done here. For that matter we will also need PostreSQL to be installed.
Data loading process has several steps to be completed in order to get the date imported into ClickHouse using denormalized schema. First we import the dataset into PostgreSQL which took about 5 hours to complete. The next step is to create TSV files for each table which took about 4 hours to complete. Then we import TSV into ClickHouse in log table format for 40 mintes more. And the last step is to create a MergeTree table which took about 1 hour. So the whole importing and denormalization process took about 11 hours to complete.
Loading Dataset into ClickHouse (Normalized)
There is an intermediate tool was used to parse the data from CSV into CH to prepare a denormalized DB state. For this normalized case we will use different loader script written in PHP which will pass the data directly to ClickHouse skipping PostgreSQL step.
Here is the table schema to store trips data:
CREATE TABLE yellow_tripdata_staging (
pickup_date Date default toDate(tpep_pickup_datetime),
id UInt64,
vendor_id String,
tpep_pickup_datetime DateTime,
tpep_dropoff_datetime DateTime,
passenger_count Int32,
trip_distance Float32,
pickup_longitude Float32,
pickup_latitude Float32,
rate_code_id String,
store_and_fwd_flag String,
dropoff_longitude Float32,
dropoff_latitude Float32,
payment_type String,
fare_amount String,
extra String,
mta_tax String,
tip_amount String,
tolls_amount String,
improvement_surcharge String,
total_amount Float32,
pickup_location_id UInt32,
dropoff_location_id UInt32,
junk1 String,
junk2 String
)
ENGINE = MergeTree(pickup_date, (id, pickup_location_id, dropoff_location_id, vendor_id), 8192);Then we run our script like this:
$ php import_taxi_data.phpThis script will only import trips data and leave external tables such weather forecast, fhv_base and fhv_zones intact. Those tables need to be loaded into PostgreSQL and used as a source for ClickHouse dictionaries.
It took 30 minutes to complete the whole import (1.3 billion records).
Prepare ClickHouse Dictionaries
ClickHouse external dictionaries is unique feature that may be used to replace traditional SQL joins. ClickHouse supports joins as well, but dictionaries are often more efficient. The detailed description of dictionaries is out of the scope of this article, but you may refer to recent Alexander’s blog post for additional info: https://altinity.com/blog/2017/4/12/dictionaries-explained. In this benchmark we will create two dictionaries: taxi_zones and weather.
Dictionaries are backed up with PSQL database tables imported with the initial script. Here is a taxi_dictionary.xml (this one should be the same for all nodes in the cluster):
<dictionaries>
<dictionary>
<name>weather</name>
<source>
<odbc>
<table>central_park_weather_observations</table>
<connection_string>DSN=psql</connection_string>
</odbc>
</source>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
<layout>
<complex_key_hashed />
</layout>
<structure>
<key>
<attribute>
<name>station_id</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>strdate</name>
<type>Date</type>
<null_value>0000-00-00</null_value>
</attribute>
</key>
<attribute>
<name>station_id</name>
<type>String</type>
<null_value/>
</attribute>
...
</structure>
</dictionary>
<dictionary>
<name>taxi_zones</name>
<source>
<odbc>
<table>taxi_zones</table>
<connection_string>DSN=psql</connection_string>
</odbc>
</source>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
<layout>
<flat />
</layout>
<structure>
<id>
<name>locationid</name>
</id>
<attribute>
<name>shape_leng</name>
<type>String</type>
<null_value />
</attribute>
...
</structure>
</dictionary>
</dictionaries>Loading Dataset into ClickHouse (Cluster)
For the third part of our benchmark we will use a ClickHouse cluster. In order to run distributed queries we need shard tables to be created at every node and special Distributed ‘umbrella’ table to access those altogether. Refer to ClickHouse documentation for details: https://clickhouse.yandex/reference_en.html#Distributed Here we use the same schema as we did for normalized dataset.
After tables are created we can pick one server where we will execute queries and create a Distributed table there with the following schema:
CREATE TABLE tripdata (
pickup_date Date default toDate(tpep_pickup_datetime),
id UInt64,
vendor_id String,
tpep_pickup_datetime DateTime,
tpep_dropoff_datetime DateTime,
passenger_count Int32,
trip_distance Float32,
pickup_longitude Float32,
pickup_latitude Float32,
rate_code_id String,
store_and_fwd_flag String,
dropoff_longitude Float32,
dropoff_latitude Float32,
payment_type String,
fare_amount String,
extra String,
mta_tax String,
tip_amount String,
tolls_amount String,
improvement_surcharge String,
total_amount Float32,
pickup_location_id UInt32,
dropoff_location_id UInt32,
junk1 String,
junk2 String
)
ENGINE = Distributed(taxi, default, yellow_tripdata, sipHash64(toString(pickup_date)));Here we use our cluster name, source table and a sharding key.
Once Distributed table is ready we can now populate it with the data. We will use our php import script with small modification of a table name so data will be sent to our Distributed table instead.
Benchmarks
After all setup is done we can proceed with the tests. There will be two stages of testing. In the first stage we are going to reproduce Mark Litwintschik’s tests in order to compare the results on a different hardware.
On the second stage we are going to use different set of queries to utilize weather and zones dictionaries in normalized database and compare the results against denormalized database.
All test queries were executed multiple times in a row and the best time has been selected as a baseline.
Mark Litwintschik’s Test Reproduction
For this test we will use our denormalized schema (which is the same as Mark used in his test) and perform the queries Mark prepared:
SELECT cab_type, count(*) FROM trips_mergetree GROUP BY cab_typeOur result: 1.2 sec (Mark’s 1 sec)
SELECT passenger_count,avg(total_amount) FROM trips_mergetree GROUP BY passenger_countOur result: 3.4 sec (Mark’s 3 sec)
SELECT passenger_count, toYear(pickup_date) AS year, count(*) FROM trips_mergetree GROUP BY passenger_count, yearOur result: 6 sec (Mark’s 5.3 sec)
SELECT passenger_count, toYear(pickup_date) AS year, round(trip_distance) AS distance, count(*) FROM trips_mergetree GROUP BY passenger_count,year, distance ORDER BY year, count(*) DESCOur result: 9.7 sec (Mark’s 12.7 sec)
So results are basically confirm that our HDDs are slower than Mark’s SSD and our CPU is faster than Mark’s. Other than that the results are similar.
Normalized Database + Dictionaries Benchmark
Now we will use queries with grouping and filtering by an attribute that comes from the dictionary.
We considered following benchmark use cases:
- “Top 10 Zones” – this query counts top 10 zones by a number of taxi trips.
- “Filter by Zone” – this query filters the dataset by a specific taxi zone name and counts the total number of trips.
- “Total trips vs temperature” – this query selects top 10 temperature values counted by a number of trips.
- “Average trip duration vs snowfall” – this query selects top 10 snowfall values grouped by average trip duration.
- “Total passenger count vs snow fall” – this query selects top 10 snowfall values grouped by a total sum of passengers amount.
These are translated in SQL as follows:
SELECT dictGetString('taxi_zones', 'zone', toUInt64(pickup_location_id)) AS zone, count() AS c FROM yellow_tripdata_staging GROUP BY pickup_location_id ORDER BY c DESC LIMIT 10
SELECT count() FROM yellow_tripdata_staging WHERE dictGetString('taxi_zones', 'zone', toUInt64(pickup_location_id)) = 'Midtown East'
SELECT dictGetFloat32('weather', 'min_temperature', ('GHCND:USW00094728', pickup_date)) AS t, count() AS c FROM yellow_tripdata_staging GROUP BY t ORDER BY c DESC LIMIT 10
SELECT dictGetFloat32('weather', 'snowfall', ('GHCND:USW00094728', pickup_date)) AS t, avg((tpep_dropoff_datetime - tpep_pickup_datetime) / 60) AS d FROM yellow_tripdata_staging GROUP BY t ORDER BY t DESC LIMIT 10
SELECT round(dictGetFloat32('weather', 'snowfall', ('GHCND:USW00094728', pickup_date))) AS t, sum(passenger_count) AS c FROM yellow_tripdata_staging GROUP BY t ORDER BY t DESC LIMIT 10Same queries were executed on single node and 3-node cluster. The result query times are summarized in the table below.
Denormalized Database Benchmark
Similar tests can be run on denormalized schema but queries needs to be modified as follows:
SELECT any(pickup_ntaname), count() AS c FROM trips_mergetree2 GROUP BY pickup_nyct2010_gid ORDER BY c DESC LIMIT 10
SELECT count() AS c FROM trips_mergetree2 WHERE pickup_ntaname = 'Midtown-Midtown South' LIMIT 10
SELECT min_temperature AS t, count() AS d FROM trips_mergetree2 GROUP BY t ORDER BY t DESC LIMIT 10
SELECT round(snowfall) AS t, avg((dropoff_datetime - pickup_datetime) / 60) AS d FROM trips_mergetree2 GROUP BY t ORDER BY t DESC LIMIT 10
SELECT round(snowfall) AS t, sum(passenger_count) AS c FROM trips_mergetree2 GROUP BY t ORDER BY t DESC LIMIT 10Benchmarks Summary
Here is the summary of tests for all three setups. As noted above, execution time is the best from several tries.
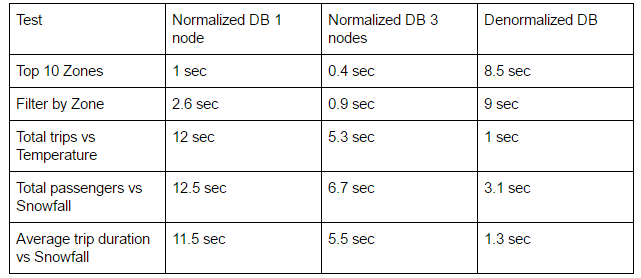
Conclusion
As we can see denormalized schema works faster than normalized in cases where grouping and ordering goes against numeric attributes. But when it comes to string attributes the dictionaries are more efficient. This is perfectly explained by the fact that dictionaries have much more compact representation of the data and do not require huge string columns to be read from the disk.
Another observation is that 3-node cluster performs twice faster when it scans and sorts the entire dataset and three times faster when the data is filtered to a much lesser amount of records. This also confirms with our understanding of how ClickHouse works internally. There is nonlinear gain when jumping from one to multiple servers, because it results in extra aggregation step at initiator node. If filter selects small amount of rows such nonlinearity becomes insignificant and the gain is close to 3 times. It worths mention that if we continue to scale up the cluster the gain should be more linear.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
This is a great article – unfortunately the benchmark summary image is no longer visible. Would be great if you add it again! Thanks
Fixed
The image showing the benchmarks is broken. Can you please fix the same?
Fixed
Please, restore Benchmarks Summary table.
Fixed