ClickHouse® vs Amazon RedShift Benchmark
Preface
We continue benchmarking ClickHouse. In this article, we discuss a benchmark against Amazon RedShift.
In our previous test we benchmarked ClickHouse database comparing query performance of denormalized and normalized schemas using NYC taxi trips dataset. Here we continue to use the same benchmark approach in order to have comparable results.
First, we compare the performance of ClickHouse at Amazon EC2 instances against private server used in the previous benchmark. Then we try the same benchmarks Amazon RedShift.
Amazon Hardware Benchmark
In order to measure the speed of the AWS virtual server, we configured r4.xlarge EC2 instance (Intel Xeon E5-2686 v4 (Broadwell), 4 vCPU, 30.5GB RAM, EBS storage)
After that we installed and configured ClickHouse there, run our test queries and compared results.
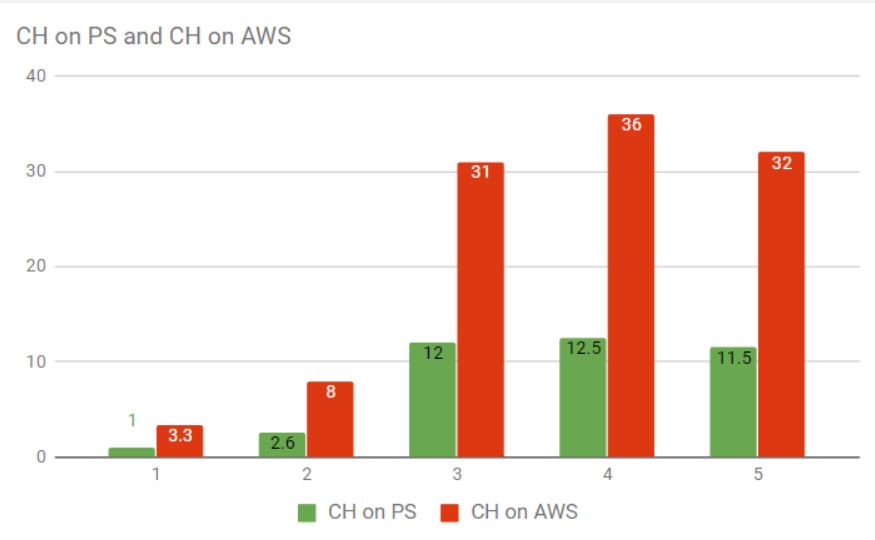
*1,2,3,4,5 are test queries
As you can see AWS virtual server is 3 times slower than our dedicated server (Intel i7-6700 Quad-Core Skylake, 32GB RAM, 2x4TB SATA). With that in hand, we could compare the results of RedShift separately.
RedShift Installation
Using AWS account we started a RedShift cluster based on ds2.xlarge profile with only one node at the beginning. ds2.xlarge is somewhat comparable to r4.xlarge, though we could not find the accurate specs. What is good about cloud platform is that you can add as many nodes as you want afterward.
To get RedShift working to receive data one has to configure special IAM role and setup security group for accessing S3 (another AWS service) so the date can get in.
Data Load into RedShift
The next step in our benchmark is to prepare DB schema and populate the data. We have used the same schema as in our ClickHouse benchmarks changing column data types when required.
In order to import the data into already prepared database schema we used updated script from our previous test that imports trip data. This script executes RedShift COPY statement for every TSV source file that should be preliminary placed to S3 storage.
A different approach was used in order to import weather and taxi zones data. We used CSV files for source data and then a couple of custom scripts that uses ODBC library in order to load data into RedShift.
RedShift Performance Benchmark
Here we used the same test queries with dictionaries as we did for the previous test for ClickHouse and original PostreSQL queries with table joins for RedShift. After executing our tests at a single node server we also scaled the cluster up to 3 nodes and re-ran the tests again.
Here are the results:
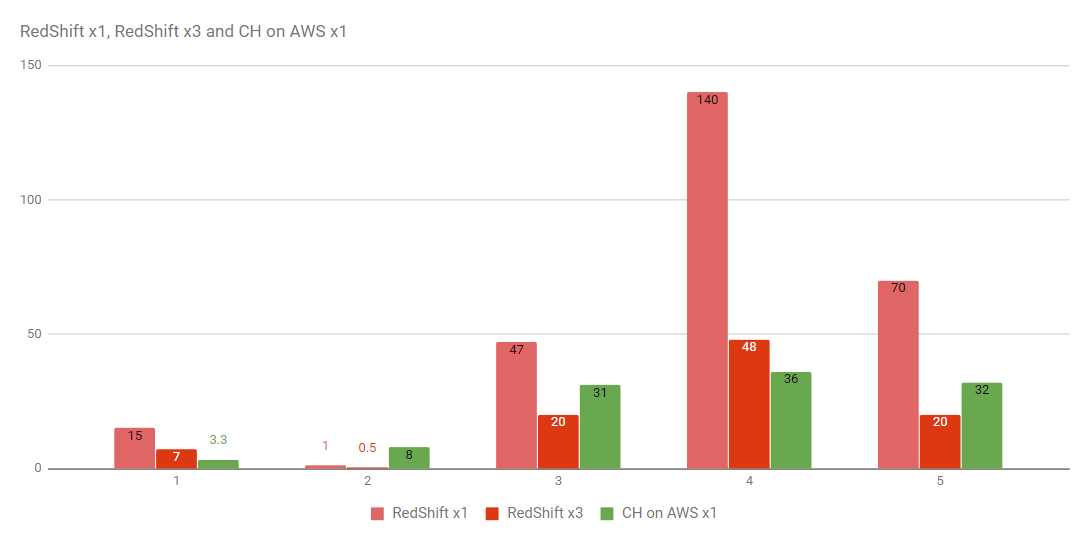
Tests confirm that ClickHouse is usually significantly faster (3-5 times) than RedShift when running on comparable Amazon instances. Even when scaling up to 3 nodes RedShift is still behind. In one test case, however, ClickHouse did run slower.
We were surprised and looked closer. For that query RedShift used efficient column predicate to filter out the data, while ClickHouse had to run dictionary lookup for every row. ClickHouse dictionaries are very fast but at 1.3 billion rows their contribution is visible.
With that said we decided to optimize the ClickHouse query. The original query used string comparison between a value from external dictionary and a string constant:
SELECT count() FROM yellow_tripdata_staging
WHERE dictGetString('taxi_zones', 'zone', toUInt64(pickup_location_id)) = 'Midtown East'The idea of optimization is to pre-cache dictionary keys or IDs (it can be done once), then filter ids in subselect and finally apply efficient ‘in’ filter to the main query. Here is how optimized query looks like:
SELECT count()
FROM yellow_tripdata
WHERE pickup_location_id IN
(
SELECT pickup_location_id
FROM pickup_location_ids
WHERE dictGetString(
'taxi_zones', 'zone', toUInt64(pickup_location_id)
) = 'Midtown East'
)The result showed that ClickHouse performing much faster with that optimization than it was before. The query time dropped down from 8 to 1.5 second.
Conclusion
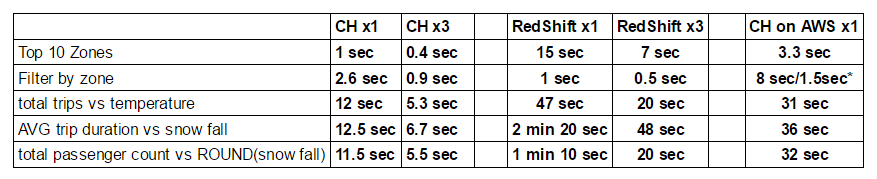
Our benchmarks show that dedicated servers are still significantly faster than Amazon instances for analytic DBMS workloads. ClickHouse is significantly faster than RedShift in most scenarios, in some cases ClickHouse queries require optimizations.
The test is not scientific, it is certainly possible to make more efficient RedShift installation and perform some optimizations on that end, but the same is true for ClickHouse. Both databases run with default settings.
P.S. We added one more benchmark against RedShift with the different dataset: https://altinity.com/blog/2017/7/3/clickhouse-vs-redshift-2
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Thanks for sharing my article about RS->CH migration!
For benchmarking CH against RS dc1.large nodes, I was planning to go with r3.large (is the closest in terms of resources for dense computing). Also is important to note that RS uses a coordination node, which is probably what makes RS slower on certain aggregations.
Regarding the compression, I did realize that the compression ratio on CH was extremely better for single tables. RS uses dictionaries for this, so if you have too many duplicated data across collections, you may benefit from that, although it affects the performance.
Thank you for the interest to you benchmarks. We have just completed one more — http://localhost:10008/blog/2017/7/3/clickhouse-vs-redshift-2
ClickHouse uses compression, simple lz4 or zstd. However, for taxi trips dataset the ratio is just 1:2.7 thanks to lat/lon, timestamps and other columns that are hard to compress (delta encoding could help here, but ClickHouse does not support it). In contrast, the compression ratio in star2002 dataset is 1:80 and can be improved even more. That is significant contributor to the query performance.
Could you please clarify EBS configuration? I.e. if it was gp2 or gp3 and if you changed default IOPS/throughput settings.
It was gp2 with default settings. See a more recent article on this topic:
http://localhost:10008/blog/clickhouse-and-redshift-face-off-again-in-nyc-taxi-rides-benchmark