Aggregate MySQL data at high speed with ClickHouse®


There are multiple ways how ClickHouse and MySQL can work together. External Dictionaries, ProxySQL support or realtime streaming of MySQL binary logs into ClickHouse. A few weeks ago ClickHouse team has released mysql() table function that allows to access MySQL data directly from ClickHouse. This opens up a number of interesting capabilities. Accidentally we have found a blog article in Japanese by Mikage Sawatari, that tests a new way of integration, and translated it for our blog with some minor edits.
Introduction
ClickHouse is a database with fast aggregation, and apparently, it is faster to run GROUP BY queries over MySQL data in ClickHouse rather than aggregating them normally in MySQL.
The following are benchmarks executed in the virtual environment, so please look at the relative numbers, absolute numbers may be different in a different environment.
Preparation of sample data
For this tests, we prepare a dataset of 10 million rows. The dataset is generated using simple Perl script and contains strings and random integers.
makedata.pl:
#!/usr/bin/perl`
use strict;
use warnings;
srand(0);
my $RECORD_COUNT = 10000000;
for(my $i = 1; $i <= $RECORD_COUNT; $i++) {
my @field;
push(@field, $i);
push(@field, sprintf("%08d@example.com", $i));
push(@field, int(rand(5))+1);
push(@field, int(rand(10))+1);
push(@field, int(rand(100000))+1);
push(@field, int(rand(1000000))+1);
push(@field, int(rand(10000000))+1);
print join("t", @field), "n";
}The resulting file is about 500 MB:
$ ./makedata.pl > data.tsv
$ ls -lh data.tsv
-rw-rw-r-- 1 mikage mikage 512M Jan 18 07:44 data.tsv
$ head -2 data.tsv
1 00000001@example.com 1 8 9638 870466 5773036
2 00000002@example.com 4 7 36877 873905 7450951Test MySQL queries
We need to create a table in MySQL and populate it. In order to test aggregation over different data types, we used different MySQL column types for number columns.
mysql> CREATE TABLE testdata (
id INT NOT NULL PRIMARY KEY,
email BLOB NOT NULL,
data1 INT NOT NULL,
data2 VARCHAR(100) NOT NULL,
data3 BLOB NOT NULL,
data4 BLOB NOT NULL,
data5 BLOB NOT NULL
) ENGINE=InnoDB;
mysql> LOAD DATA LOCAL INFILE 'data.tsv' INTO TABLE testdata;
Query OK, 10000000 rows affected (44.98 sec)
Records: 10000000 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT data1, COUNT(*) FROM testdata GROUP BY data1;
+-------+----------+
| data1 | COUNT(*) |
+-------+----------+
| 1 | 2000453 |
| 2 | 1999993 |
| 3 | 1998988 |
| 4 | 1999013 |
| 5 | 2001553 |
+-------+----------+
5 rows in set (3.22 sec)
mysql> SELECT data2, COUNT(*) FROM testdata GROUP BY data2;
+-------+----------+
| data2 | COUNT(*) |
+-------+----------+
| 1 | 1000530 |
| 10 | 999424 |
| 2 | 1000648 |
| 3 | 1000357 |
| 4 | 998349 |
| 5 | 998889 |
| 6 | 999786 |
| 7 | 998774 |
| 8 | 1001805 |
| 9 | 1001438 |
+-------+----------+
10 rows in set (4.01 sec)
mysql> SELECT data3, COUNT(*) FROM testdata GROUP BY data3;
-- Results omitted
100000 rows in set (3 min 32.82 sec)
mysql> SELECT data1, COUNT(DISTINCT data5) FROM testdata GROUP BY data1;
+-------+-----------------------+
| data1 | COUNT(DISTINCT data5) |
+-------+-----------------------+
| 1 | 1813005 |
| 2 | 1812503 |
| 3 | 1812072 |
| 4 | 1811674 |
| 5 | 1814106 |
+-------+-----------------------+
5 rows in set (3 min 3.56 sec)It seems to be pretty slow to do GROUP BY with BLOB type.
Test ClickHouse queries
You can use MySQL data on ClickHouse by specifying it with the table function instead of a table name.
mysql('host:port', 'database', 'table', 'user', 'password)Let’s start the ClickHouse client and test it.
SELECT
data1,
COUNT(*)
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
GROUP BY data1
┌─data1─┬─COUNT()─┐
│ 4 │ 1999013 │
│ 3 │ 1998988 │
│ 2 │ 1999993 │
│ 5 │ 2001553 │
│ 1 │ 2000453 │
└──────┴──────────┘
5 rows in set. Elapsed: 2.685 sec. Processed 10.00 million rows, 40.00 MB (3.72 million rows/s., 14.90 MB/s.)
SELECT
data2,
COUNT(*)
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
GROUP BY data2
┌─data2─┬─COUNT()─┐
│ 6 │ 999786 │
│ 8 │ 1001805 │
│ 9 │ 1001438 │
│ 3 │ 1000357 │
│ 2 │ 1000648 │
│ 4 │ 998349 │
│ 5 │ 998889 │
│ 10 │ 999424 │
│ 1 │ 1000530 │
│ 7 │ 998774 │
└──────┴──────────┘
10 rows in set. Elapsed: 2.692 sec. Processed 10.00 million rows, 101.00 MB (3.71 million rows/s., 37.52 MB/s.)
SELECT
data3,
COUNT(*)
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
GROUP BY data3
-- Results omitted
100000 rows in set. Elapsed: 5.236 sec. Processed 10.00 million rows, 138.89 MB (1.91 million rows/s., 26.52 MB/s.)
SELECT
data1,
uniqExact(data5)
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
GROUP BY data1
┌─data1─┬─uniqExact(data5)─┐
│ 4 │ 1811674 │
│ 3 │ 1812072 │
│ 2 │ 1812503 │
│ 5 │ 1814106 │
│ 1 │ 1813005 │
└──────┴───────────────────┘
5 rows in set. Elapsed: 12.944 sec. Processed 10.00 million rows, 198.89 MB (772.55 thousand rows/s., 15.37 MB/s.)ClickHouse has a function to calculate a unique number roughly, so let’s calculate it there.
SELECT
data1,
uniq(data5)
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
GROUP BY data1
┌─data1─┬─uniq(data5)─┐
│ 4 │ 1812684 │
│ 3 │ 1811607 │
│ 2 │ 1817432 │
│ 5 │ 1815763 │
│ 1 │ 1815300 │
└──────┴──────────────┘
5 rows in set. Elapsed: 6.026 sec. Processed 10.00 million rows, 198.89 MB (1.66 million rows/s., 33.00 MB/s.)As you can see quite time-consuming queries in MySQL can also be processed in a very short time in ClickHouse.
When the query is being executed multiple times, it may be better to copy the data over to ClickHouse. So subsequent queries will be faster.
In this example, we will use StripeLog engine.
CREATE TABLE testdata
ENGINE = StripeLog AS
SELECT *
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
Ok.
0 rows in set. Elapsed: 9.823 sec. Processed 10.00 million rows, 917.66 MB (1.02 million rows/s., 93.42 MB/s.)If you have a primary key, you may also want to use the MergeTree table. This is the engine which is mostly used in ClickHouse. It is necessary to specify the sort order of data with ORDER BY (note, it is no problem if there are duplicates in the data)
CREATE TABLE testdata
ENGINE = MergeTree
ORDER BY id AS
SELECT *
FROM mysql('localhost', 'mikage', 'testdata', 'mikage', '')
Ok.
0 rows in set. Elapsed: 20.466 sec. Processed 10.00 million rows, 917.66 MB (488.61 thousand rows/s., 44.84 MB/s.)I will try the previous query.
Below is the test results with the StripeLog engine.
SELECT
data1,
COUNT(*)
FROM testdata
GROUP BY data1
┌─data1─┬─COUNT()─┐
│ 4 │ 1999013 │
│ 3 │ 1998988 │
│ 2 │ 1999993 │
│ 5 │ 2001553 │
│ 1 │ 2000453 │
└──────┴──────────┘
5 rows in set. Elapsed: 0.071 sec. Processed 10.00 million rows, 40.00 MB (141.13 million rows/s., 564.53 MB/s.)
SELECT
data2,
COUNT(*)
FROM testdata
GROUP BY data2
┌─data2─┬─COUNT()─┐
│ 6 │ 999786 │
│ 8 │ 1001805 │
│ 9 │ 1001438 │
│ 3 │ 1000357 │
│ 2 │ 1000648 │
│ 4 │ 998349 │
│ 5 │ 998889 │
│ 10 │ 999424 │
│ 1 │ 1000530 │
│ 7 │ 998774 │
└──────┴──────────┘
10 rows in set. Elapsed: 0.177 sec. Processed 10.00 million rows, 101.00 MB (56.34 million rows/s., 569.05 MB/s.)
SELECT
data3,
COUNT(*)
FROM testdata
GROUP BY data3
--- Results omitted
100000 rows in set. Elapsed: 0.779 sec. Processed 10.00 million rows, 138.89 MB (12.84 million rows/s., 178.29 MB/s.)
SELECT
data1,
uniqExact(data5)
FROM testdata
GROUP BY data1
┌─data1─┬─uniqExact(data5)─┐
│ 5 │ 1814106 │
└──────┴───────────────────┘
┌─data1─┬─uniqExact(data5)─┐
│ 1 │ 1813005 │
└──────┴───────────────────┘
┌─data1─┬─uniqExact(data5)─┐
│ 4 │ 1811674 │
└──────┴───────────────────┘
┌─data1─┬─uniqExact(data5)─┐
│ 3 │ 1812072 │
└──────┴───────────────────┘
┌─data1─┬─uniqExact(data5)─┐
│ 2 │ 1812503 │
└──────┴───────────────────┘
5 rows in set. Elapsed: 1.725 sec. Processed 10.00 million rows, 198.89 MB (5.80 million rows/s., 115.32 MB/s.)
SELECT
data1,
uniq(data5)
FROM testdata
GROUP BY data1
┌─data1─┬─uniq(data5)─┐
│ 4 │ 1812684 │
│ 3 │ 1811607 │
│ 2 │ 1817432 │
│ 5 │ 1815763 │
│ 1 │ 1815300 │
└──────┴──────────────┘
5 rows in set. Elapsed: 0.285 sec. Processed 10.00 million rows, 198.89 MB (35.03 million rows/s., 696.62 MB/s.)Summary
Below is the summary table. From the left to right, the query time in MySQL, the query time of ClickHouse using MySQL data with mysql() function, and the query time to run the queries over the copied data in ClickHouse.
Altinity note : As you can see it demonstrates how fast is ClickHouse comparing to MySQL. Even if the data is in MySQL it still processes it faster, and once the data is copied over to ClickHouse it becomes blazingly fast. With new mysql() function is very easy to move static data from MySQL to ClickHouse. If you need realtime streaming, refer to https://github.com/Altinity/clickhouse-mysql-data-reader or similar approaches.
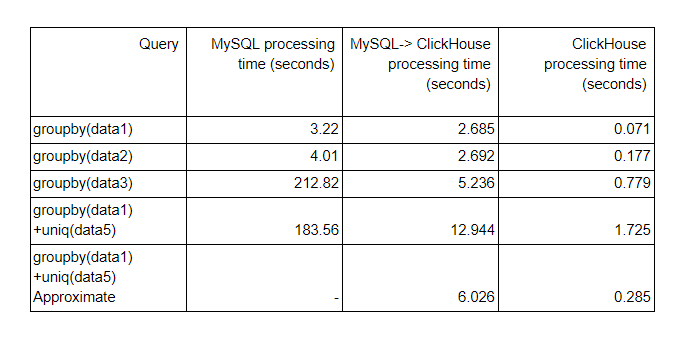
Appendix: datatype mapping
When ClickHouse maps MySQL data, if there is no corresponding data type on ClickHouse side, it seems to use String. For example, there is no corresponding type for Decimal type, so ClickHouse uses String instead. If you want to treat it as a numerical value, the precision will change, but it seems necessary to keep Double type on MySQL side.
Also, Date and DateTime types have different ranges in MySQL and ClickHouse. In ClickHouse both will be by 1970-2038 ( Altinity note: that was in original text, in fact, the range has been extended to 2105 a few months ago). If there is data outside the range, it may be necessary to make it String type, divide the column by year, month, day and copy it as a numerical value.
You can find the type mapping in ClickHouse source code: https://github.com/yandex/ClickHouse/blob/9965f5e357f1be610608a51dc7a41f89c2321275/dbms/src/TableFunctions/TableFunctionMySQL.cpp#L37
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Hello, What about JOINS?
Hello, What about JOINS?