Circular Replication Cluster Topology in ClickHouse®
Important Note: Altinity no longer recommends using a circular replication topology in ClickHouse. We’re keeping the article up for historical reasons. If you want to run multiple servers on a smaller number of hosts consider using Kubernetes and the Altinity Kubernetes Operator for ClickHouse.
Introduction
In some cases, there is a need to configure a distributed cluster with replication but there are not enough servers in order to place every replica on a separate node. It is better to have multiple replicas at the same nodes configured in a special way, that allows to continue executing queries even in the case of a node failure. Such replication configuration can be found in different distributed systems, it is often referred to as ‘circular’ or ‘ring’ replication. In this article, we will discuss how to set up circular replication in ClickHouse. If you are new to this topic, we suggest starting with an introductory article “ClickHouse Data Distribution”.
Concept
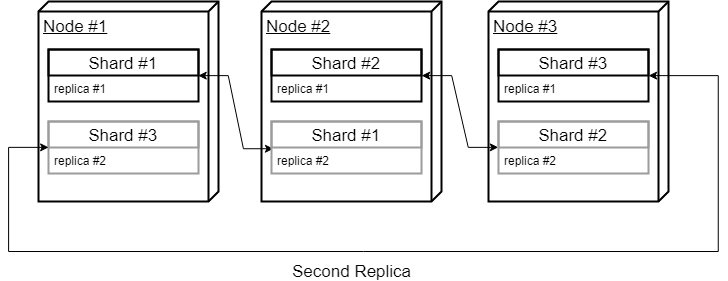
Assume there are 3 servers and 1 table. The goal is to have data distributed in 3 shards and replicated twice. That requires 2 different shards located on every node.
Cluster Configuration
Let’s start with a straightforward cluster configuration that defines 3 shards and 2 replicas. Since we have only 3 nodes to work with, we will setup replica hosts in a “Circle” manner meaning we will use the first and the second node for the first shard, the second and the third node for the second shard and the third and the first node for the third shard. Just like so:
- 1st shard, 1st replica, hostname: cluster_node_1
- 1st shard, 2nd replica, hostname: cluster_node_2
- 2nd shard, 1st replica, hostname: cluster_node_2
- 2nd shard, 2nd replica, hostname: cluster_node_3
- 3rd shard, 1st replica, hostname: cluster_node_3
- 3rd shard, 2nd replica, hostname: cluster_node_1
The configuration section may look like this:
<shard>
<replica>
<host>cluster_node_1</host>
</replica>
<replica>
<host>cluster_node_2</host>
</replica>
</shard>
<shard>
<replica>
<host>cluster_node_2</host>
</replica>
<replica>
<host>cluster_node_3</host>
</replica>
</shard>
<shard>
<replica>
<host>cluster_node_3</host>
</replica>
<replica>
<host>cluster_node_1</host>
</replica>
</shard>As you can see now we have the following storage schema:
- cluster_node_1 stores 1st shard, 1st replica and 3rd shard, 2nd replica
- cluster_node_2 stores 1st shard, 2nd replica and 2nd shard, 1st replica
- cluster_node_3 stores 2nd shard, 2nd replica and 3rd shard, 1st replica
That obviously does not work, since shards have the same table name and ClickHouse cannot distinguish one shard/replica from another when they are located at the same server. The trick here is to put every shard into a separate database! ClickHouse allows to define ‘default_database’ for each shard and then use it in query time in order to route the query for a particular table to the right database.
One more important note about using “Circle” topology with ClickHouse is that you should set a internal_replication option for each particular shard to TRUE. It is defined as follows:
<shard>
<internal_replication>true</internal_replication>
<replica>
<default_database>testcluster_shard_1</default_database>
<host>cluster_node_1</host>
</replica>
<replica>
<default_database>testcluster_shard_1</default_database>
<host>cluster_node_2</host>
</replica>
</shard>Now let’s try to define shard tables that correspond to this configuration.
Database Schema
As discussed above, in order to separate shards between each other on the same node shard-specific databases are required.
- Schemas of the 1st Node
- testcluster_shard_1
- testcluster_shard_3
- Schemas of the 2nd Node
- testcluster_shard_2
- testcluster_shard_1
- Schemas of the 3rd Node
- testcluster_shard_3
- testcluster_shard_2
Replicated Table Schema
Now let’s setup replicated tables for shards. ReplicatedMergeTree table definition requires two important parameters:
- Table Shard path in Zookeeper
- Replica Tag
Zookeeper path should be unique for every shard, and Replica Tag should be unique within each particular shard:
1st Node:
CREATE TABLE testcluster_shard_1.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_1/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_3.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_3/events’, ‘replica_2’, …)2nd Node:
CREATE TABLE testcluster_shard_2.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_2/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_1.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_1/events’, ‘replica_2’, …)3nd Node:
CREATE TABLE testcluster_shard_3.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_3/events’, ‘replica_1’, …)
CREATE TABLE testcluster_shard_2.tc_shard
…
Engine=ReplicatedMergeTree(‘/clickhouse/tables/tc_shard_2/events’, ‘replica_2’, …)Distributed Table Schema
The only remaining thing is distributed table. In order ClickHouse to pick proper default databases for local shard tables, the distributed table needs to be created with an empty database. That triggers the use of default one.
CREATE TABLE tc_distributed
…
ENGINE = Distributed( ‘testcluster’, ‘’, tc_shard, rand() )When query to the distributed table comes, ClickHouse automatically adds corresponding default database for every local tc_shard table.
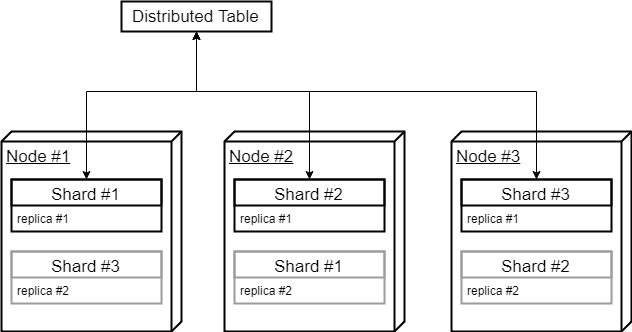
It makes sense to have ‘load_balancing’ setting set to ‘in_order’, otherwise, ClickHouse may occasionally select second replicas for query execution, resulting in two shards queried from the same cluster node that is not optimal.
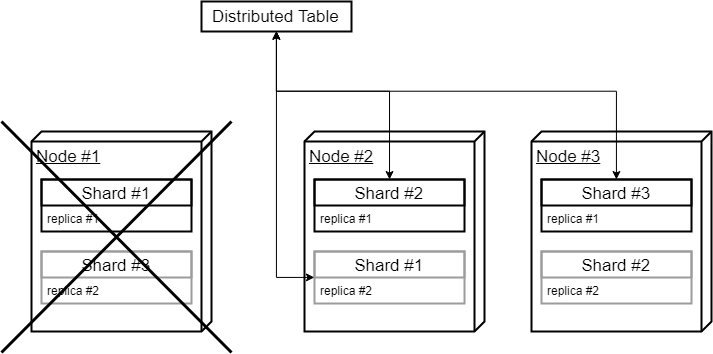
If one of the nodes is down, there is still enough data to run queries:
Conclusion
As shown above, it is possible to setup circular or ring replication topology in ClickHouse, though it is not straightforward, requires non-evident configuration and additional databases to separate shards and replicas. In addition to a complex configuration, such setup performs worse comparing to separate replica nodes due to double INSERT load for every cluster node. While it may seem attractive to re-use same nodes for replicas, the performance and configuration concerns need to be taken into account when considering circular replication deployment.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
Thank Andrey for the awesome post, I just have followed you guide and config 3 nodes. But when I tried to query data, with the same query condition, I got multiple results.
After that, I tried to change the value of
internal_replicationconfig from the default (it’sfalse) to<internal_replication>true</internal_replication>and everything work well.Is this the problem or I did wrong somewhere?
Hello!
Thanks for pointing this thing out. You are correct of using internal_replication in case of a "Circle" topology. We have missed that indeed in the article.
We hava added that information to the text now. Thank you!
Hello, I use this command to insert data to clickhouse, but only db varnish_shard_2 has data and data is not distributed to db varnish_shard_1 and varnish_shard_3.cat varnishncsa.log| clickhouse-client -h clh1 –password 1 –input_format_skip_unknown_fields=1 –date_time_input_format=’best_effort’ –query="INSERT INTO varnish_shard_2.vn_shard FORMAT JSONEachRow"Below is my config:<shard> <internal_replication>true</internal_replication> <replica> <default_database>varnish_shard_2</default_database> <host>clh2</host> <port>9000</port> <user>default</user> <password>1</password> </replica> <replica> <default_database>varnish_shard_2</default_database> <host>clh3</host> <port>9000</port> <user>default</user> <password>1</password> </replica> </shard>shard 1 and 3 is same with varnish_shard_1 and 3.Was I wrong somewhere ?
Hello, I use this command to insert data to clickhouse, but only db varnish_shard_2 has data and data is not distributed to db varnish_shard_1 and varnish_shard_3.
cat varnishncsa.log| clickhouse-client -h clh1 –password 1 –input_format_skip_unknown_fields=1 –date_time_input_format=’best_effort’ –query="INSERT INTO varnish_shard_2.vn_shard FORMAT JSONEachRow"
Below is my config:
<shard>
<internal_replication>true</internal_replication>
<replica>
<default_database>varnish_shard_2</default_database>
<host>clh2</host>
<port>9000</port>
<user>default</user>
<password>1</password>
</replica>
<replica>
<default_database>varnish_shard_2</default_database>
<host>clh3</host>
<port>9000</port>
<user>default</user>
<password>1</password>
</replica>
</shard>
shard 1 and 3 is same with varnish_shard_1 and 3.
Was I wrong somewhere ?
And what if You need to add one more shard?..
And what if You need to add one more shard?..
true
node1
9600
node2
9700
true
node2
9600
node3
9700
true
node3
9600
node1
9700
this way ddl can work
Hi , I followed above circular topology but I am facing below issue while fetching data from distributed table.
Received from my-wk-03.sample.com:9000. DB::Exception: Database `testcluster_shard_1` doesn’t exist.
Please help.
Hi!
There could be a couple of problems.
1.) Are you missing schema? Make sure you have defined the database and table on all shards. In current ClickHouse versions you can issue ON CLUSTER commands, e.g., CREATE DATABASE IF NOT EXISTS test_cluster_shard1 ON CLUSTER ‘mycluster’. Replace mycluster with your actual cluster name.
2.) Is this really the right name? Usually you’ll want to use the same database and table names across all shards and replicas. The distributed table can’t SELECT data if schema names are different.
3.) Did you define the distributed table correctly? It’s easy to mix up cluster, database, and table arguments. Most of us make that mistake at some point. 🙁
Cheers, Robert