Realtime replication from MySQL to ClickHouse® in practice

Vladislav Klimenko from Altinity and Valery Panov from Ivinco presented a talk on HighLoad Siberia 2018 conference recently. They described the real problem that Ivinco faced and how it has been solved with migration of analytics from MySQL into ClickHouse using MySQL to ClickHouse replication. A few months ago we introduced clickhouse-mysql tool in our blog, and Ivinco was the first company we know that tried it, and used it in production.
Ivinco problem
Ivinco is working on a large scale search engine project which provides REST API for near-realtime full-text search.
The data is news articles, blog posts, social media messages, and it is acquired from multiple data sources (project partners). Data size is around 200TB in MySQL and ~25TB in Manticore Search.
Customers use REST API search service to analyze this data for marketing researches, PR campaigns effectiveness evaluation and business awareness.
Each REST API call produces various operational metrics such as timings, involved data sets, query path and many other items, which are written into MySQL. Statistics data are kept in daily MySQL tables (like perormance_log_YYmmdd) with 30 days retention.
Performance data is used by Ivinco admins for service performance analysis and monitoring. For example, following typical queries may be asked:
- Number of queries per day, grouped by keys
- Number of queries per day dynamics
- Query time distribution over subsystems (PHP time, MySQL time, Manticore search time, Redis time, etc)
- System performance degradation
- How hardware and software updates impact performance in general and each subsystem personally (PHP time, MySQL time, Manticore search time, Redis time, etc)
- Timings comparison per period (day, week, month, etc)
- Failed queries dynamics and many, many others
Such an approach works fine, but there are several bottlenecks, such as:
- It is difficult to extend data retention, MySQL is hard to scale
- HA and failover issues. Easy-to-use multi-master replication wanted
- MySQL requires many indexes, typically every type of query requires a separate index. That leads to dozens of indexes per table.
- Using daily MySQL tables resulted in bad cross-day queries
Ivinco considered several possible solutions:
- Keep working with MySQL, struggling with all mentioned above issues – looks like it is not the way to go.
- Migrate to ELK stack – completely different world, too many changes and development resources are required
- NoSQL – analytics team was not happy, asked for something more convenient
- Clickhouse – has SQL dialect close to MySQL and general “likeliness” of MySQL to an end user – so Ivinco decided to give it a try.
However, given the importance of the stability of the current system and limited resources, there were following requirements for the migration project:
- Seamless and transparent. Current system should be minimally affected
- Development resources are limited, so the less development is needed — the better
- The core logging and data collection functionality should not be touched at all to minimize risks
ClickHouse solution
At first, Ivinco team tried the straightforward approach, installing ClickHouse as a direct replacement of MySQL and mirroring the schema all log records there. That did not work very well facing the following issues:
- Mirroring MySQL schema into ClickHouse was not optimal and there were the same issues with cross-day queries as in MySQL. ClickHouse deals easily with huge tables, so there is no need to manually partition data in different tables.
- Incorrect choice of Primary Key – tried to include as many columns as possible into PK, based on previous MySQL experience. ClickHouse does not like huge Primary Keys.
- Writing the same data to MySQL and ClickHouse was problematic without significant development efforts
So the first approach failed and Ivinco decided to change it as follows:
- Use Clickhouse cluster from the beginning for replication and sharding.
- Proper Primary Key selection. ClickHouse’s speed has been impressive
- Use clickhouse-mysql for data migration
That approach perfectly worked, and we will discuss it in more detail now.
clickhouse-mysql
Ivinco case is not unique. It is pretty common that some old mature systems are built with MySQL. Legacy systems are often hard to modify, and developers may be busy with other projects. The initiative to migrate ClickHouse may come from DevOps team that has to deal with all MySQL problems. So whatever changes are made to the system has to be done on DevOps side with minimum involvement of core developers. The is where clickhouse-mysql helps. So let’s see how it works in more detail.
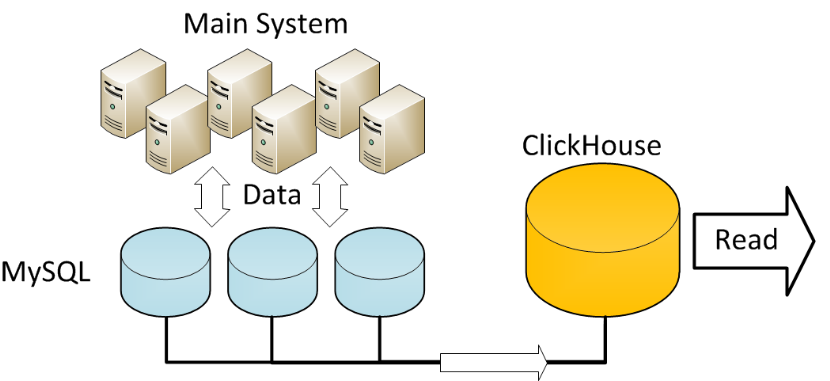
The main challenge is to move data from MySQL to ClickHouse. There are several ways to do that:
- Run something like SELECT FROM MySQL -> INSERT INTO ClickHouse. Polling as it is.
- ClickHouse provides MySQL storage engine, so it is possible to access MySQL data directly.
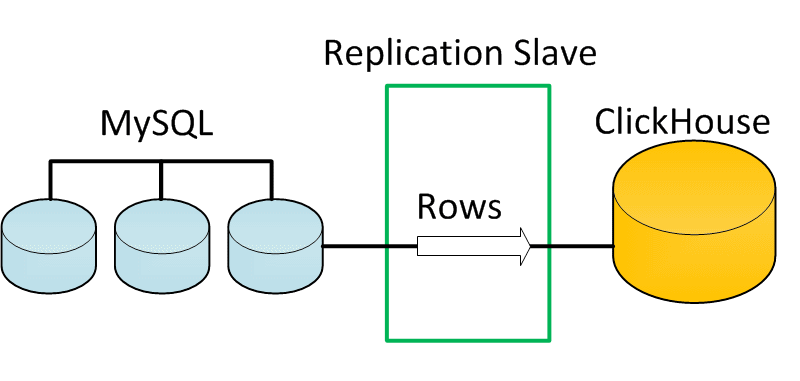
- Introduce replication slave for MySQL that writes to ClickHouse.
The latter approach seems to be the most convenient since it allows maximum flexibility and customization:
- no polling at all – MySQL is active and send all the data as soon as it gets
- awareness of other data events, such as UPDATE/DELETE, etc.
- data transformations are possible before writing to ClickHouse
clickhouse-mysql has been developed with those ideas in mind, it is feature rich and provides the following functionality:
- Migrate existing data (bootstrapping)
- Migrate incoming data
- Schema migrator and templater, which helps to create ClickHouse schema based on schema in MySQL.
- Data filters and transformers
- Plugins – in case something custom is needed, there is an option to process data stream with additional code.
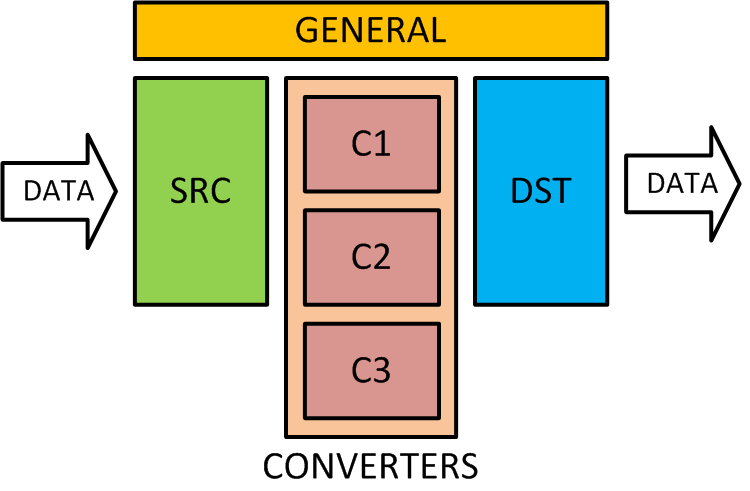
clickhouse-mysql can be logically separated into 4 main parts:
- application backbone
- source handlers
- destination handlers
- converters that provide flexibility in configuration.
Comprehensive documentation of clickhouse-mysql and some examples can be found in http://github.com/Altinity/clickhouse-mysql-data-reader/README.md.
Ivinco tried clickhouse-mysql and found it really useful. They also provided reasonable feedback to Altinity that helped to improve the tool. The project has been successful:
- Seamless data migration from MySQL into ClickHouse
- No work for dev team on this stage
- All ClickHouse power is available for analytics and monitoring
- Now when queries are switched to ClickHouse, dev team may work on direct logging into ClickHouse without any time pressure in order to get rid of MySQL eventually.
Conclusion
This project was a good collaboration for both Ivinco and Altinity. It demonstrated how easily ClickHouse can be used as an analytical backend for existing MySQL solution.
ClickHouse® is a registered trademark of ClickHouse, Inc.; Altinity is not affiliated with or associated with ClickHouse, Inc.
How to achieve incremental and real-time
well thanks alot for such a nice article, but i have a question, can we use mysql for incoming data, like when data is coming, we can use mysql features like autoincrement and other, and just for reading, we can move incoming data to clickhouse from mysql table, in short, we will keep inserting data to mysql first, then from mysql to clickhouse, and for analytics we will read data from clickhouse instead of mysql, will this scenario work within limited system resources ? your answer will be very appreciated.